Deadlock, Blocking Lock
Deadlocks and blocking locks are often confused. The symptoms are similar and both are related to contention for database resources by multiple processes. However blocking locks and deadlocks differ in a number of ways. The most important difference is that the process holding a lock that blocks other processes will eventually complete and release the lock so the waiting processes can proceed.
A deadlock will not resolve itself. SQL Server runs a system process that looks for deadlocks and rolls back one or another of the processes to allow the remaining process to proceed. SQL Server chooses the victim by looking at the cost to roll back each process. It chooses the less expensive one.
(Most deadlocks involve two processes, but in some cases there may be more. For simplicity, we will discuss only deadlocks involving two processes blocking each other.)
Deadlocks threaten data consistency because a command from the application has to be killed and the data rolled back. The application must trap deadlocks and take appropriate action when a command is rolled back. For example, a process might be updating the invoice table to mark an invoice as paid. The process might end up as the victim in a deadlock situation and the change it made rolled back. If the application does not detect the deadlock and take appropriate action, then the data remains incorrect and the company may end up with an irate customer.
Let’s illustrate a deadlock by taking a very common example: a deadlock involving two processes that try to update rows on the same page of a table. By default, an update begins by the process taking a shared lock on the table. (The lock does not necessarily have to lock the entire table, but it is much simpler to describe what happens if we just assume it is a table lock.) After the process finds the data it wants to update, it has to convert its shared lock into an exclusive lock to be able to change the data.
Imagine that two processes attempt to update data at roughly the same time. Both acquire a shared lock. When they find the data they want to update, both try to convert their shared lock to an exclusive lock. While both can have a shared lock on the same data, neither can get an exclusive lock on it because of the shared lock the other is holding. This is called the “deadly embrace”. The processes would hold their locks forever if SQL Server did not step in very quickly and kill one process.
How Do You Fix Deadlocks?
Fixing deadlocks can be very complicated. We will mention a couple of common solutions but this short article cannot tell you everything you need to know about fixing deadlocks. However, the first step is always to gather all the information you can about the deadlock and we can help you with that.
Ancient History
In versions of SQL Server earlier than SQL 2005 you could only get information about deadlocks through a clumsy process of running certain trace flags that would monitor for deadlocks and write the deadlock information to the SQL error log. This had a number of disadvantages, the worst of which was that many people set these very expensive trace flags and then forgot about them. I have encountered many instances where these trace flags had been hobbling SQL Server performance for years. When I asked about them, no one currently involved with the SQL Server knew when or why they were implemented.
Deadlock Graph
With the release of SQL Server 2005, gathering deadlock information got a lot easier. That version of SQL Profiler contained a new event called “Deadlock Graph” under the Lock category. When a deadlock occurs, Deadlock Graph generates an xml document containing everything you need to know about the deadlock. In the same SQL Server version, both Management Studio and Profiler were enhanced to display this xml data in a very intuitive graphical format. Even the xml-challenged can now take in most of the deadlock information at a glance.
You can also save the XML to a file and open it in an XML reader like XMLNotepad, a free download from Microsoft.
http://www.microsoft.com/download/en/details.aspx?id=7973
Viewing the xml data gives you quite a bit more information about the deadlock. XMLNotepad displays the data in a much more readable text format than browsing the raw xml. This is the method we prefer.
Using Deadlock Graph
If you are having deadlock issues, open SQL Profiler and create a new trace. Select a blank template and then add the deadlock graph event from the Locks group. When you select this event, notice that a new tab labeled “Events Extraction Settings” appears on the Trace Properties window. Select that tab and select “Save Deadlock XML Events Separately”. Specify a directory and a file name. Select the radio button “All XML Events in a Single File”. Then start the trace.
Let the trace run until you have captured one or more deadlocks. Rather than display the raw XML, Profiler will display the graphical rendering of the deadlock information. If you hover your mouse over various parts of the Profiler display, windows will pop up with more detailed data. You will get the same graphical display if you open the saved file in Management Studio.

Beyond the Graphical Display
For the rest of the article we will be discussing the data as viewed by opening the file in an XML reader rather than using the graphical display. However, even if you plan to use only the graphical display you should read the rest of the article for the discussion of how to interpret the individual data items.
Renaming the File
Note that the file in which you saved the deadlock information has an .xsd file extension. XSD is a special Microsoft extension that tells Profiler and Management Studio to render the contents in the graphical display format. In order to open this file in an XML reader like XMLNotepad you need to change the extension to .xml. Since I am frequently working on a client’s computer using remote desktop, I often open the file using Notepad and copy the data. I paste the text into XMLNotepad on my own computer and save the file with the .xml extension.
Understanding the Deadlock Data
When you open the XML file in XMLNotePad you will see a deadlock node for each deadlock.
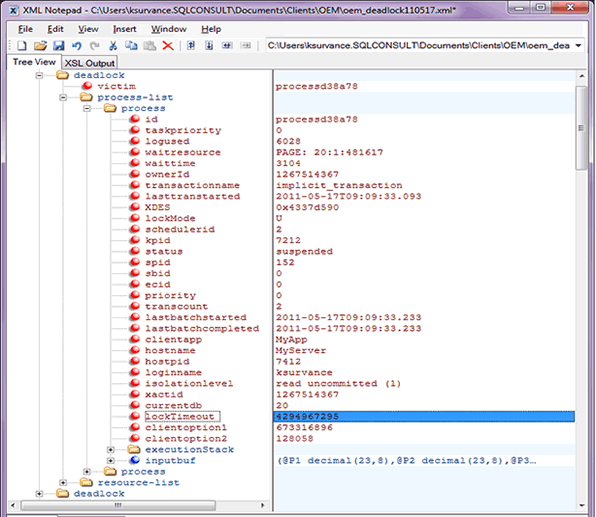
If you expand a deadlock node you will see three nodes beneath it. The victim node contains only one data point, the process id of the process that was chosen as the deadlock victim. The process-list contains a process node for every process involved in the deadlock. The resource-list node contains information for each resource involved in the deadlock.
It is the individual process and resource nodes that contain the most important data points. Among all these nodes there are more than a hundred data points, so we cannot explain each one individually. However we will explain the most important of them below.
We will begin with the Process nodes.
lockMode
Knowing the mode of lock held by this process is important recognizing the kind of deadlock you are dealing with. If you do not recognize the abbreviations used by Microsoft, you can look up the SQL Server lock modes here.
Transcount
Nesting level of the transaction. Is it a simple transaction or is it a transaction within a transaction?
Clientapp
The application that executed this SQL command. This often helps in identifying the source of the command.
Hostname
Another help in identifying where the problem is coming from.
Loginname
Yet another help in identifying the source.
Isolationlevel
This is very important and is your first clue about how to fix the problem. If the process is running in a too restrictive isolation mode, changing the mode (if possible) just might solve the problem.
For example, a process running in “readcommitted” isolation mode will hold a shared lock on the data it is reading, preventing any change to the data while the lock is held. You might fix the problem by reducing the isolation level to “readuncommitted” (NOLOCK in the old syntax). No lock will be taken on the resource. This depends of course on the data consistency needs of the application.
Inside the executionStack node we find other important information
Procname
If the code executed is a stored procedure, the name will be here.
#text
Bingo, here is the text of one of the commands involved in the deadlock. With this information from all the resource nodes, you might discover how and why the deadlock is occurring.
inputbuf
The last statement issued by this process. This is often a copy of the text of the command.
Inside the Resource-list node you will find information to help you identify the resource involved in the deadlock.
Dbid
This is of course the ID of the database holding the resource.
Objectname
The name of the object in which the deadlock is occurring.
Indexname
Knowing the index where the problem is occurring might give you some options for fixing the problem. For example, some deadlocks occur because a lock is escalated from a rowlock to a pagelock. If that turns out to be your problem, you might consider disallowing page locks on this index. You must test this carefully before putting the change in production because disallowing page locks can be a performance problem in some cases.
Mode
Knowing the mode of the lock is important for solving the deadlock problem. In contrast to the LockMode attribute in the Process node, this is the mode of the lock currently held on the resource in question. If you do not recognize the lock mode displayed here, you can look up the SQL Server lock modes here. http://msdn.microsoft.com/en-us/library/ms175519.aspx
The owner-list and waiter-list nodes contain data that will help you sort out which process was holding which locks.
Conclusion
This was short essay into a very large topic. There is a lot to learn about the many kinds of deadlocks that can occur and this newsletter is much too short to give you all the information you need to fix them. However knowing the details of the deadlock is a good start. Hopefully we have put the necessary tools into your hands to find the information you need to have to fix a deadlocking situation.